OCR 自定义模板识别(支持表格识别)
文字识别(OCR)目前在多个行业中得到了广泛应用,比如金融行业的单据识别输入,餐饮行业中的发票识别,交通领域的车票识别,企业中各种表单识别,以及日常工作生活中常用的身份证,驾驶证,护照识别等等。OCR(文字识别)是目前常用的一种AI能力。一般OCR的识别结果是一种按行识别的结构化输出,能够给出一行文字的检测框坐标及文字内容。但是我们更想要的是带有字段定义的结构化输出,由于表单还活着卡证的多样性,全都预定义好是不现实的。 所以,设计了自定义模板的功能,能够让人设置参照锚点(通过锚点匹配定位,图片透视变换对齐),以及内容识别区来得到key-value形式的结构化数据。
当前精简试用版(无数据库,redis等)包含了下面功能:
- 模板自定义
- 基于模板识别
- 自由文本识别
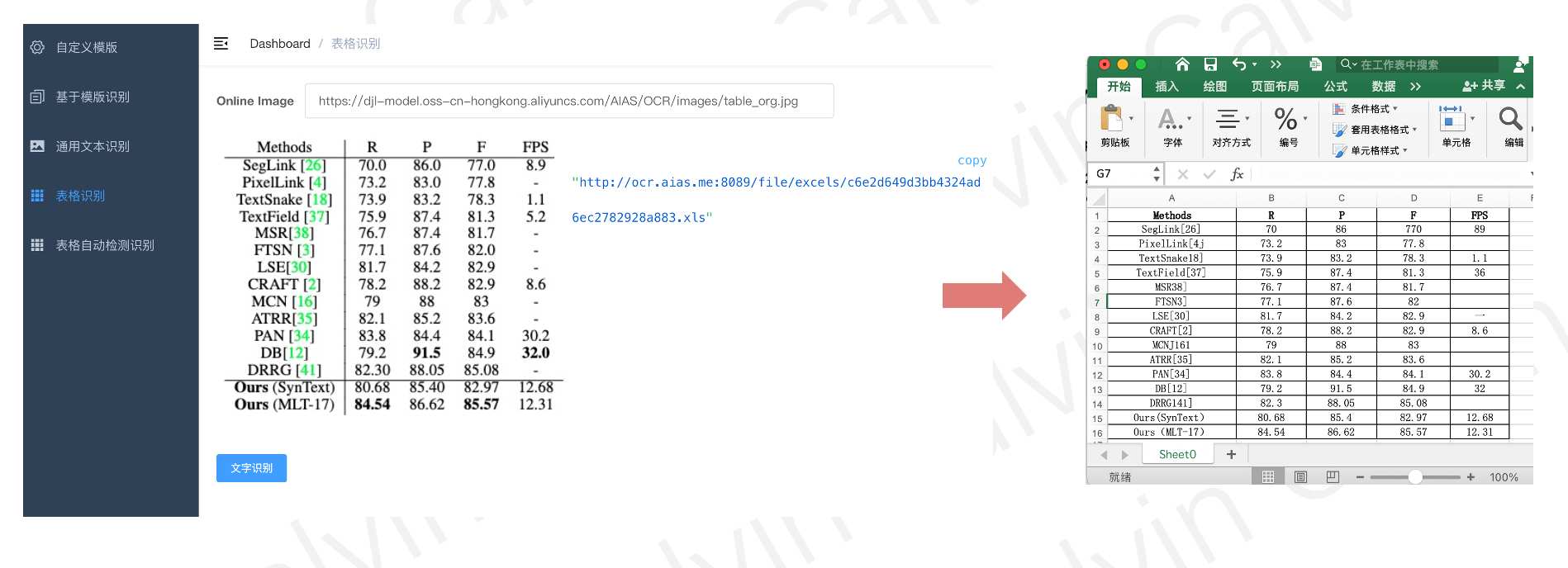
- 表格文本识别(图片需是剪切好的单表格图片)
- 表格自动检测文本识别(支持表格文字混编,自动检测表格识别文字,支持多表格) (需要图片都是摆正的,即没有旋转角度。)
功能介绍
打开浏览器
输入地址: http://localhost:8080
标注模板
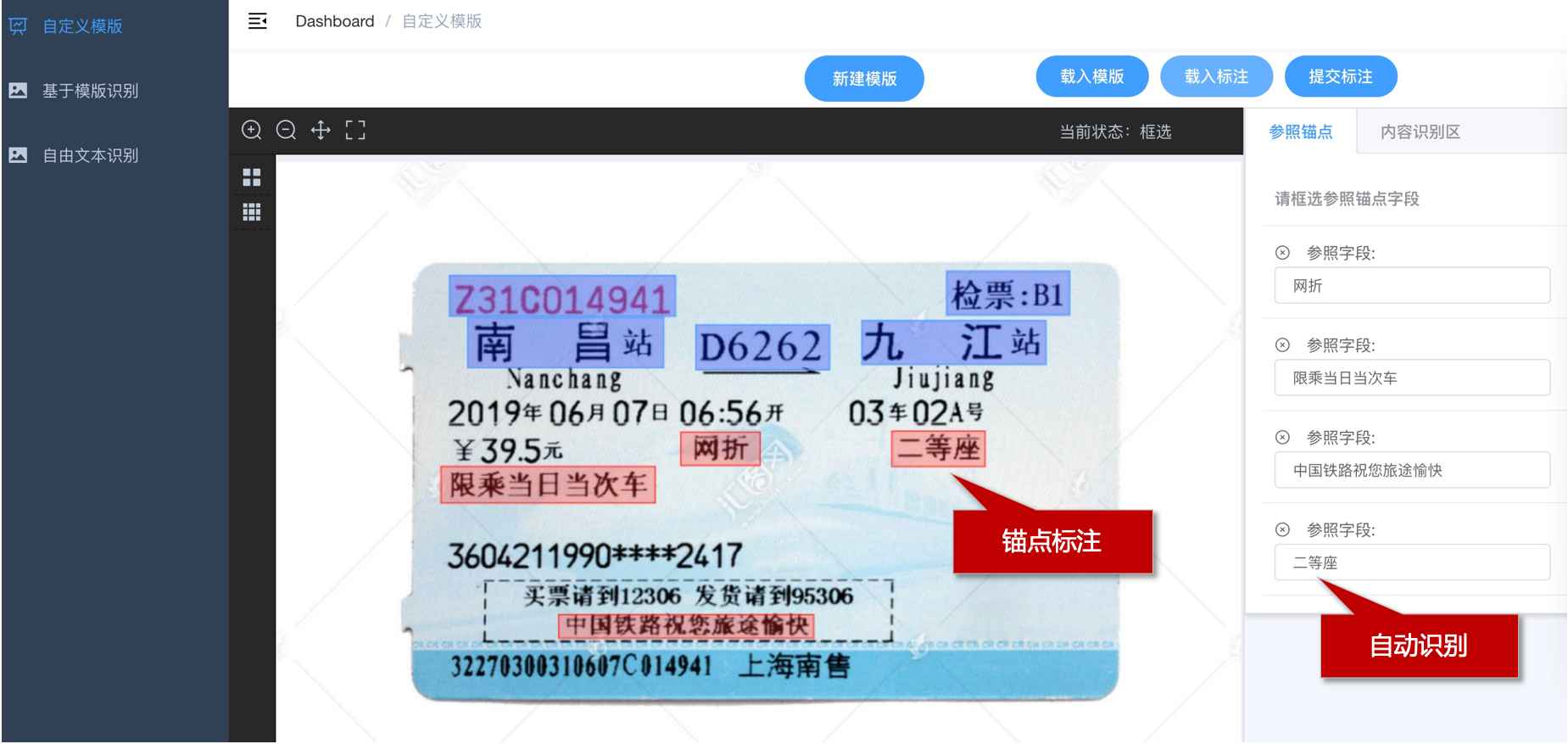
xxxxxxxxxx# 参照锚点设置规则:1. 建议框选4个及以上(最少3个)参照字段,并尽量分散(向四角方向) 1). 如果匹配4个及以上的锚点框,则进行透视变换 2). 如果匹配3个锚点框,则进行仿射变换 3). 如果匹配的锚点少于三个则直接根据相对坐标计算2. 参照锚点必须是位置固定不变,文字固定不变3. 单个参照字段不可跨行,且中间没有大片空白4. 参照锚点文字内容需唯一,即不会重复出现的文字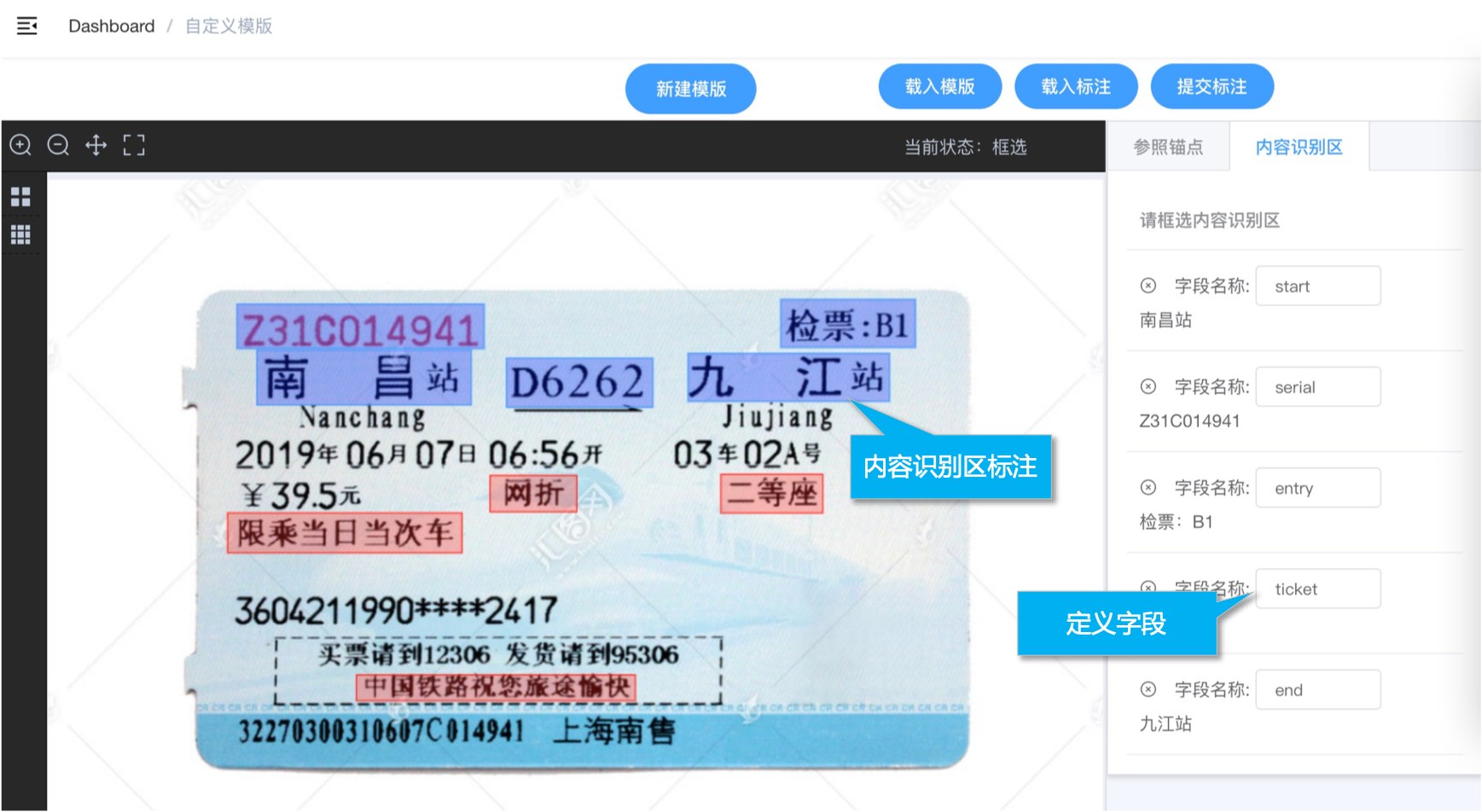
xxxxxxxxxx# 内容识别区设置规则:1. 识别结果以<key,value>形式展示,字段名需手工设置2. 字段名需使用有业务意义的字母数字组合,如:name,age, address3. 字段名不能含有特殊字符及空格基于模板文字识别
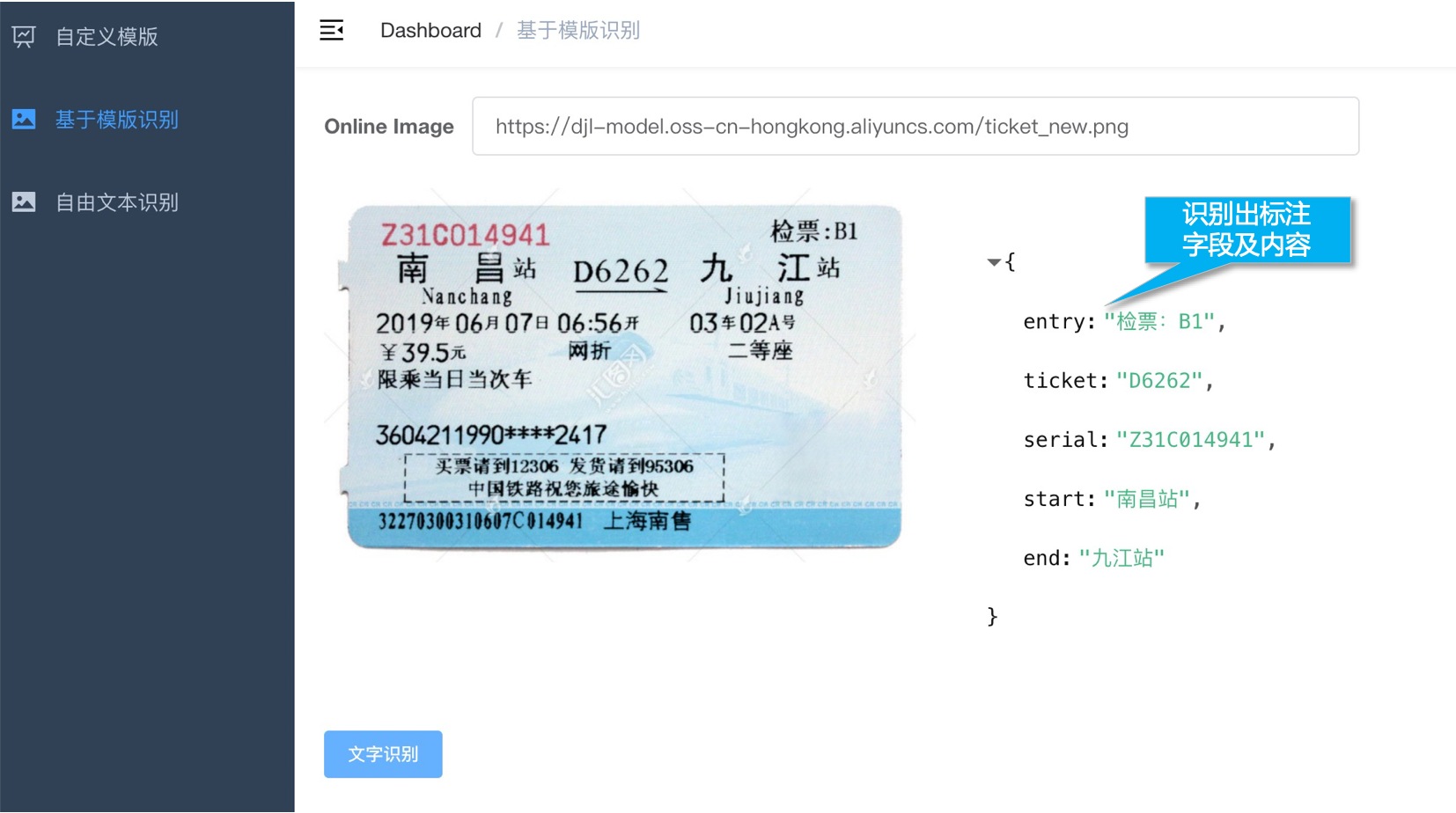
通用文本识别

表格文字识别 / 表格自动检测文字识别
项目源代码下载: