人工智能技术如何与大数据技术栈协同工作?
人工智能模型训练很大程度依赖标注的数据。而需要标注数据量大的话,离不开大数据平台提供技术支持。 训练好的模型,反过来同样可以用于大数据技术栈。
场景1:ToB
在企业内部的大数据平台中,有两个典型环节可能用到人工智能技术:
- 数据采集环节 - 非结构化数据解析,如:图片,文本,音频等。
- 数据挖掘分析服务 - 图片搜索,基于深度学习的推荐,NLP问答,智能客服等。
- 人工智能 & 大数据

场景2:泛安防
近几年,人工智能在泛安防领域得到了广泛的应用。 人脸识别技术目前已经广泛应用于包括人脸门禁系统、刷脸支付等各行各业。随着人脸识别技术的提升,应用越来越广泛。目前中国的人脸识 别技术已经在世界水平上处于领先地位,在安防行业,国内主流安防厂家也都推出了各自的人脸识别产品和解决方案,泛安防行业是人脸识别技术主要应用领域。 这个例子给出了人脸识别技术是如何与大数据技术栈协同工作的。后续结合人脸特征提取,特征向量保存到向量搜索引擎,形成人像底库,然后就可以实现人像大数据搜索。 安防领域一个典型的架构,如下图所示。端边侧提取出含人像的大小图后,发送到云端,由云端的更高精度的大模型来继续处理。
- 端边云架构
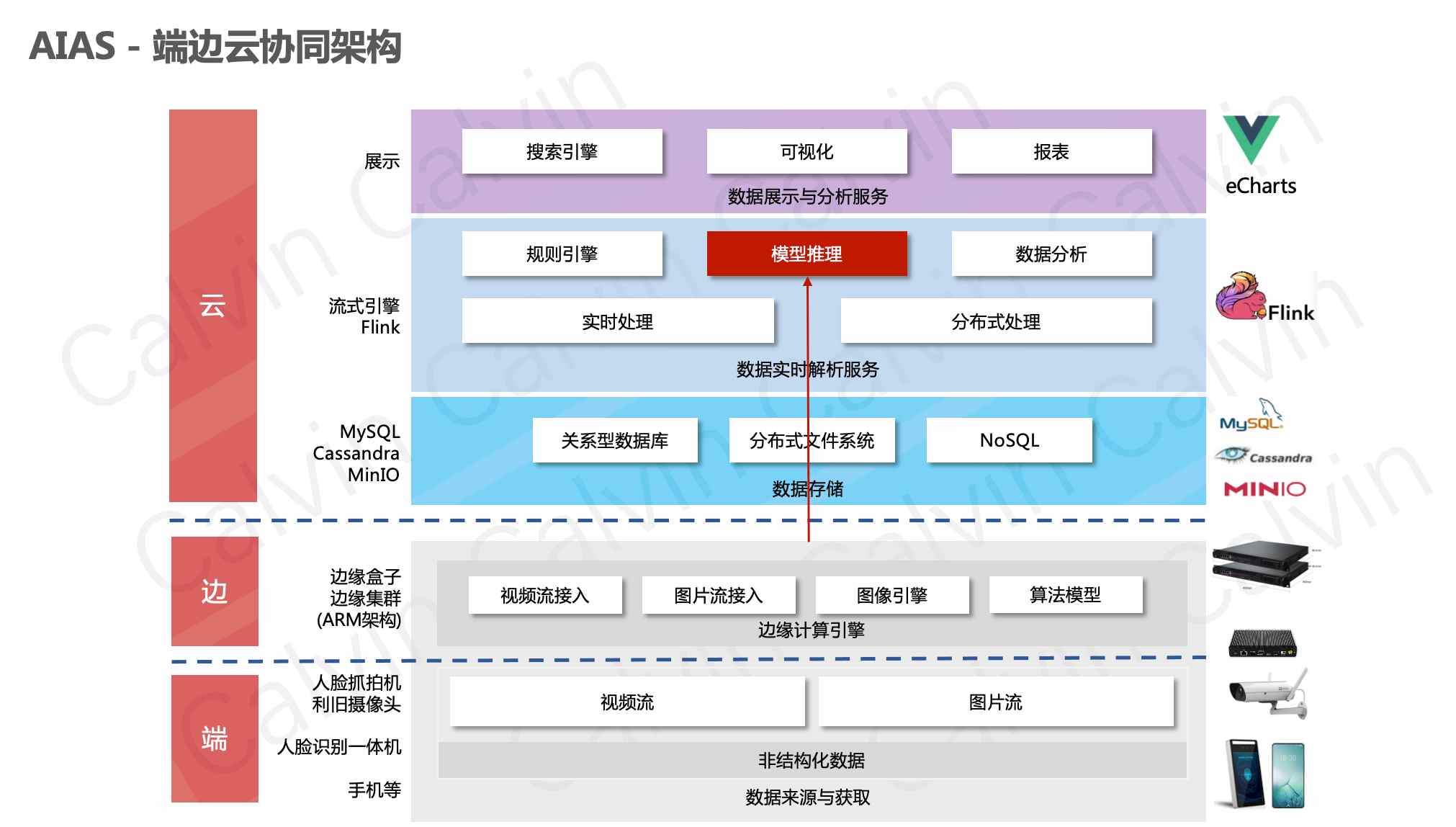
- 人脸检测

图像识别 - kafka,flink,人脸识别
下面的例子给出了图像识别结合kafka,flink协同工作的流程:
1. 启动 zookeeper:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
2. 启动 kafka:
启动前先需环境配置kafka的server.properties(添加message.max.bytes=10485760), 支持大消息。
因为图片转成base64字符串后,会超过kafka的默认消息大小设置。如果不增加配置,kafka不会接收消息。
kafka-server-start /usr/local/etc/kafka/server.properties
3. 创建 topic:
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic face-data
4. 查看创建的topic
kafka-topics --list --zookeeper localhost:2181
5. 运行例子 - FaceDetectionExample
flink启动,并监听kafka的"face-data"topic。
6. 运行例子 - MyKafkaProducer
读取图片,转成base64格式发送给kafka的"face-data"topic。
7. 查看 FaceDetectionExample的输出Console
consumer接受到图片的base64数据, 转换成图片并解析:
[ class: "Face", probability: 0.99958, bounds: [x=0.485, y=0.198, width=0.122, height=0.230] class: "Face", probability: 0.99952, bounds: [x=0.828, y=0.270, width=0.116, height=0.225] class: "Face", probability: 0.99937, bounds: [x=0.180, y=0.234, width=0.119, height=0.231]]SDK代码下载地址: