语义搜索 - 重排序(Re-Rank) SDK【英文】
对于复杂的搜索任务,通过使用 Retrieve & Re-Rank 的流水线可以显著提高搜索的精度。
Retrieve & Re-Rank Pipeline
信息检索 / 问题问答检索的典型流水线: 给定一个查询语句,我们首先使用一个检索系统获取一个比较大的返回列表,比如:100条相关的数据。检索系统可以使用ElasticSearch,也可以使用向量搜索引擎(通过bi-encoder提取特征),如:faiss。但是,搜索系统返回的结果可能跟查询语句不是太相关(比如搜索引擎为考虑性能,会牺牲一点精度),这时,我们可以在第2阶段,使用一个基于cross-encoder的重排序器(re-ranker),对返回的结果进行重排序。然后将重排序的结果呈现给最终用户。
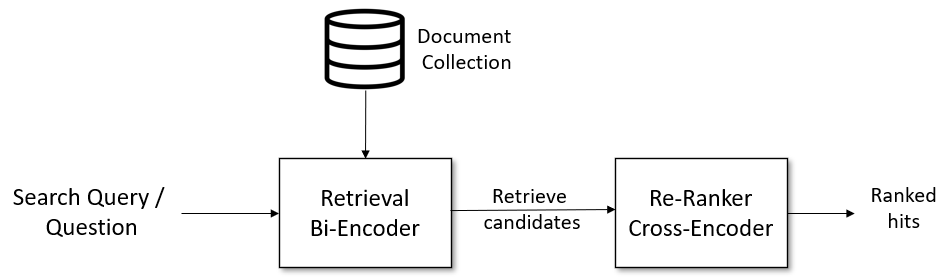
Retrieval: Bi-Encoder
语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本。模型基于MS MARCO数据集训练,可以用于语义搜索,如:关键字 / 搜索短语 / 问题,模型可以找到跟查询query相关的passages。MS MARCO是微软发布了的一套问答组成的数据集,人工智能领域的研究人员可用它来构建能够与真人相媲美的问答系统。 这套数据集全称:Microsoft MAchine Reading COmprehension,意为“微软机器阅读理解”。MS MARCO是目前同类型中最有用的数据集,因为它建立在经过匿名处理的真实世界数据(Bing搜索引擎的搜索查询数据)基础之上。
Bi-Encoder可以使用下面的模型: https://github.com/mymagicpower/AIAS/tree/main/nlp_sdks/qa_retrieval_msmarco_s_sdk
Re-Ranker: Cross-Encoder
搜索引擎对于大量文档的检索效率很高,但是,它可能会返回不相关的候选项。这时,基于Cross-Encoder的重排序器的引入,可以进一步优化返回的结果。 它将查询语句与之前获得的候选项,同时传入一个网络,获取相关度的分数,然后通过这个分数进行重排序。
SDK功能:
- 相似度计算 (max_seq_length 512)
运行例子
运行成功后,命令行应该看到下面的信息:
x...# 测试QA语句:[INFO ] - input query1: [How many people live in Berlin?, Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.][INFO ] - input query2: [How many people live in Berlin?, Berlin is well known for its museums.]
#计算相似度分数:[INFO ] - Score1: 7.1523676[INFO ] - Score2: -6.2870417