图像&文本的跨模态相似性比对检索 SDK【英文】
背景介绍
OpenAI 发布了两个新的神经网络:CLIP 和 DALL·E。它们将 NLP(自然语言识别)与 图像识别结合在一起,对日常生活中的图像和语言有了更好的理解。
之前都是用文字搜文字,图片搜图片,现在通过CLIP这个模型,可是实现文字搜图片,图片搜文字。其实现思路就是将图片跟文本映射到同一个向量空间。如此,就可以实现图片跟文本的跨模态相似性比对检索。
- 特征向量空间(由图片 & 文本组成)

CLIP,“另类”的图像识别
目前,大多数模型学习从标注好的数据集的带标签的示例中识别图像,而 CLIP 则是学习从互联网获取的图像及其描述, 即通过一段描述而不是“猫”、“狗”这样的单词标签来认识图像。 为了做到这一点,CLIP 学习将大量的对象与它们的名字和描述联系起来,并由此可以识别训练集以外的对象。
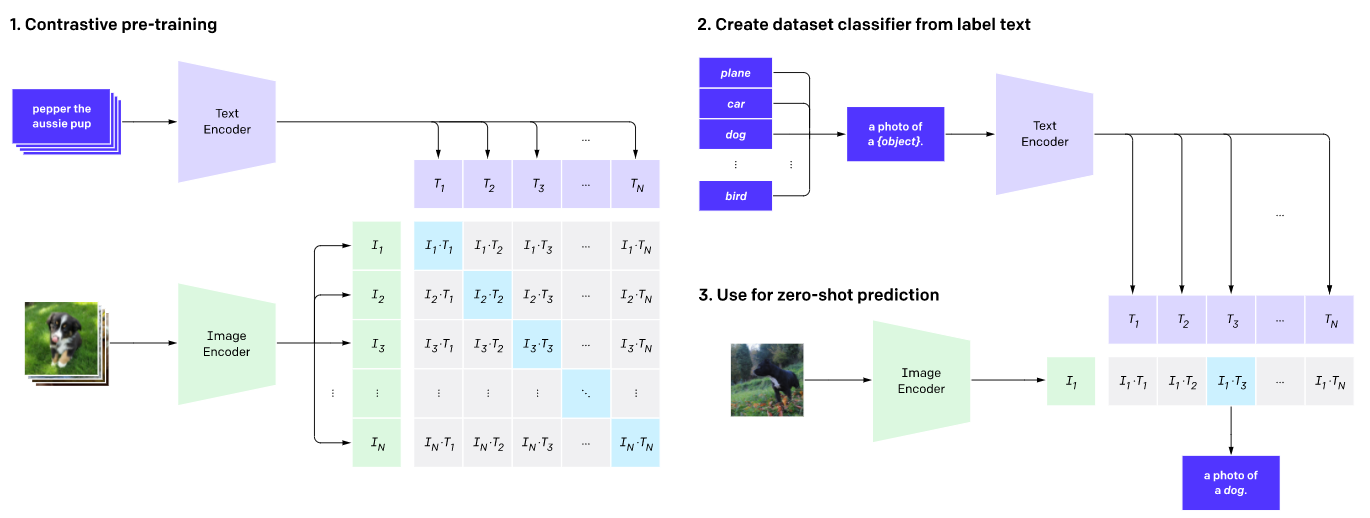
如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
SDK功能:
- 图像&文本特征向量提取
- 相似度计算
- softmax计算置信度
运行例子
运行成功后,命令行应该看到下面的信息:
x...# 测试文本 & 图片:[INFO ] - texts: [a diagram, a dog, a cat][INFO ] - image: src/test/resources/CLIP.png
# 向量维度:[INFO ] - Vector dimension: 512
# 生成图片向量:[INFO ] - image embeddings: [0.44528162, -0.24093077, ..., -0.14698291, 0.097667605]
# 生成文本向量 & 计算相似度:[INFO ] - text [a diagram] embeddings: [0.05469787, -0.006111175, ..., -0.12809977, -0.49502343][INFO ] - Similarity: 26.80176%[INFO ] - text [a dog] embeddings: [0.14469987, 0.022480376, ..., -0.34201097, 0.17975798][INFO ] - Similarity: 20.550625%[INFO ] - text [a cat] embeddings: [0.19806248, -0.20402007, ..., -0.56643164, 0.05962909][INFO ] - Similarity: 20.786627%
#softmax 计算置信度:[INFO ] - Label probs: [0.9956493, 0.0019198752, 0.0024309014]