句向量SDK【支持15种语言】
句向量是指将语句映射至固定维度的实数向量。 将不定长的句子用定长的向量表示,为NLP下游任务提供服务。 支持 15 种语言: Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
- 句向量
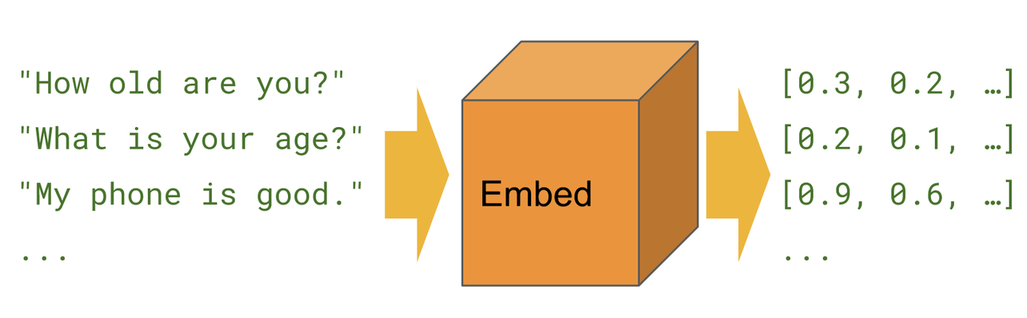
句向量应用:
- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
SDK功能:
- 句向量提取
- 相似度(余弦)计算
运行例子
运行成功后,命令行应该看到下面的信息:
x...# 测试语句:# 英文一组[INFO ] - input Sentence1: This model generates embeddings for input sentence[INFO ] - input Sentence2: This model generates embeddings
# 中文一组[INFO ] - input Sentence3: 今天天气不错[INFO ] - input Sentence4: 今天风和日丽
# 向量维度:[INFO ] - Vector dimensions: 512
# 英文 - 生成向量:[INFO ] - Sentence1 embeddings: [-0.07397884, 0.023079528, ..., -0.028247012, -0.08646198][INFO ] - Sentence2 embeddings: [-0.084004365, -0.021871908, ..., -0.039803937, -0.090846084]
#计算英文相似度:[INFO ] - 英文 Similarity: 0.77445346
# 中文 - 生成向量:[INFO ] - Sentence1 embeddings: [0.012180057, -0.035749275, ..., 0.0208446, -0.048238125][INFO ] - Sentence2 embeddings: [0.016560446, -0.03528302, ..., 0.023508975, -0.046362665]
#计算中文相似度:[INFO ] - 中文 Similarity: 0.9972926
SDK代码下载地址: